

In this article, we show you how you can use Python to analyze ahrefs backlink data to find link building opportunities for your site.
- Motivation: Find link building opportunities
- Downloading backlink profiles from ahrefs
- Loading ahrefs backlink data into Python
- Cleaning the ahrefs backlink data
- Creating ahrefs link intersect reports
- Export data to Excel
- Show link building opportunities
Motivation: Find link building opportunities
One technique to find backlink opportunities is to analyze your competitor's backlink profiles and compare those with your own backlinks.
This way, you can find links your competitors have but you don't (yet).
For this reason, the tool ahrefs created the Link Intersect report. However, this report is only available to the higher-paid plans.
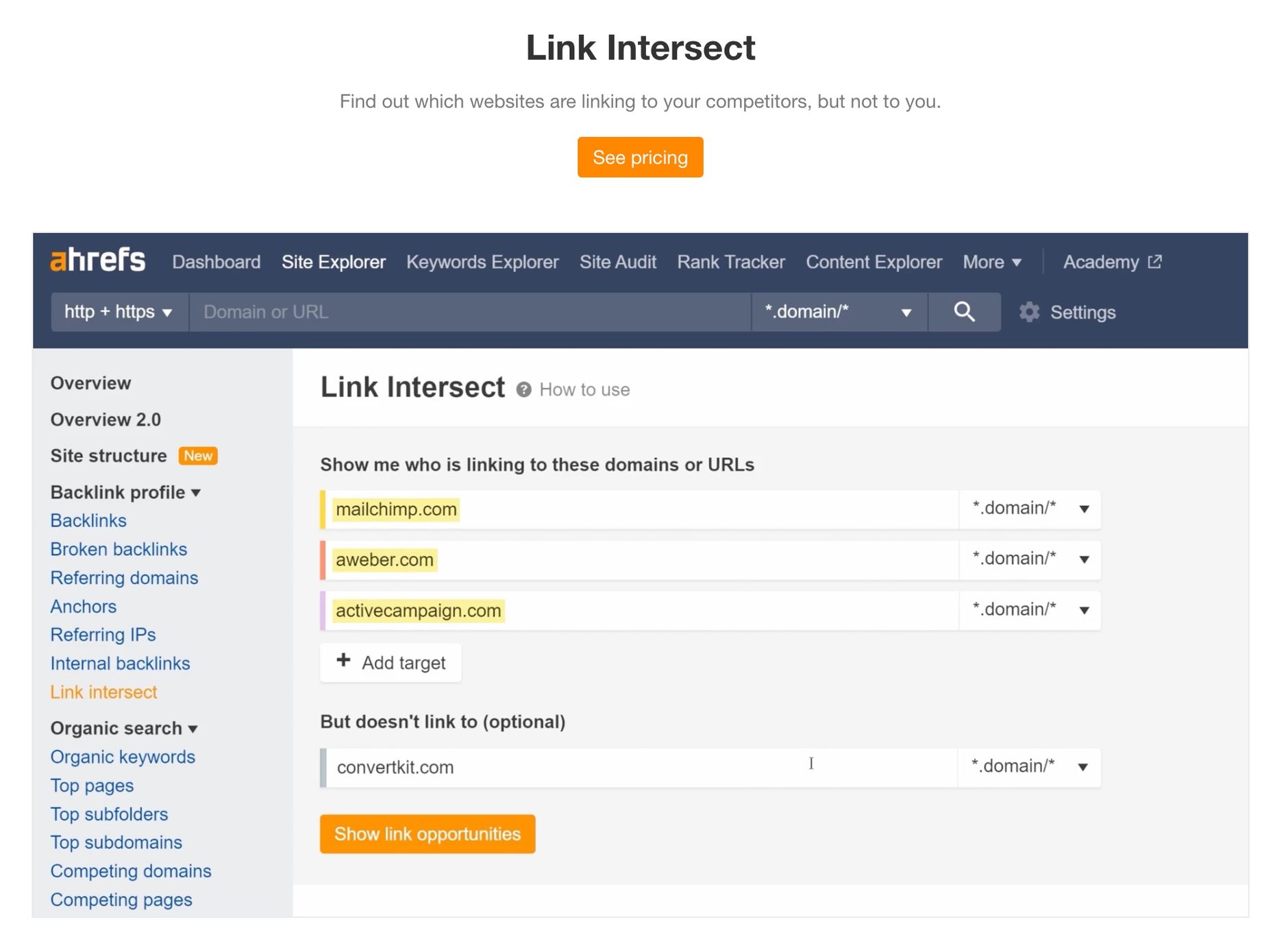
In this article, we'll show you how to replicate this report.
It would certainly be possible to do this in Excel, but by using powerful tools like Python and Jupyter Notebooks this task becomes way easier, especially if you want to repeat this analysis multiple times. The script only needs seconds to run, while doing this by hand takes much longer.
In this example, we use data from ahrefs, but we you could use any tool that provides backlink data. You would need to update the respective column names.
We'll use ahrefs own example and assume we are the SEO expert for convertkit.com and want to find link building opportunities by looking at selected the following competitors:
- mailchimp.com
- aweber.com
- activecampaign.com
Downloading backlink profiles from ahrefs
First, we need to download the respective backlink profiles.
To do this, we go to the "Backlinks" section and search for the domain we are interested in.
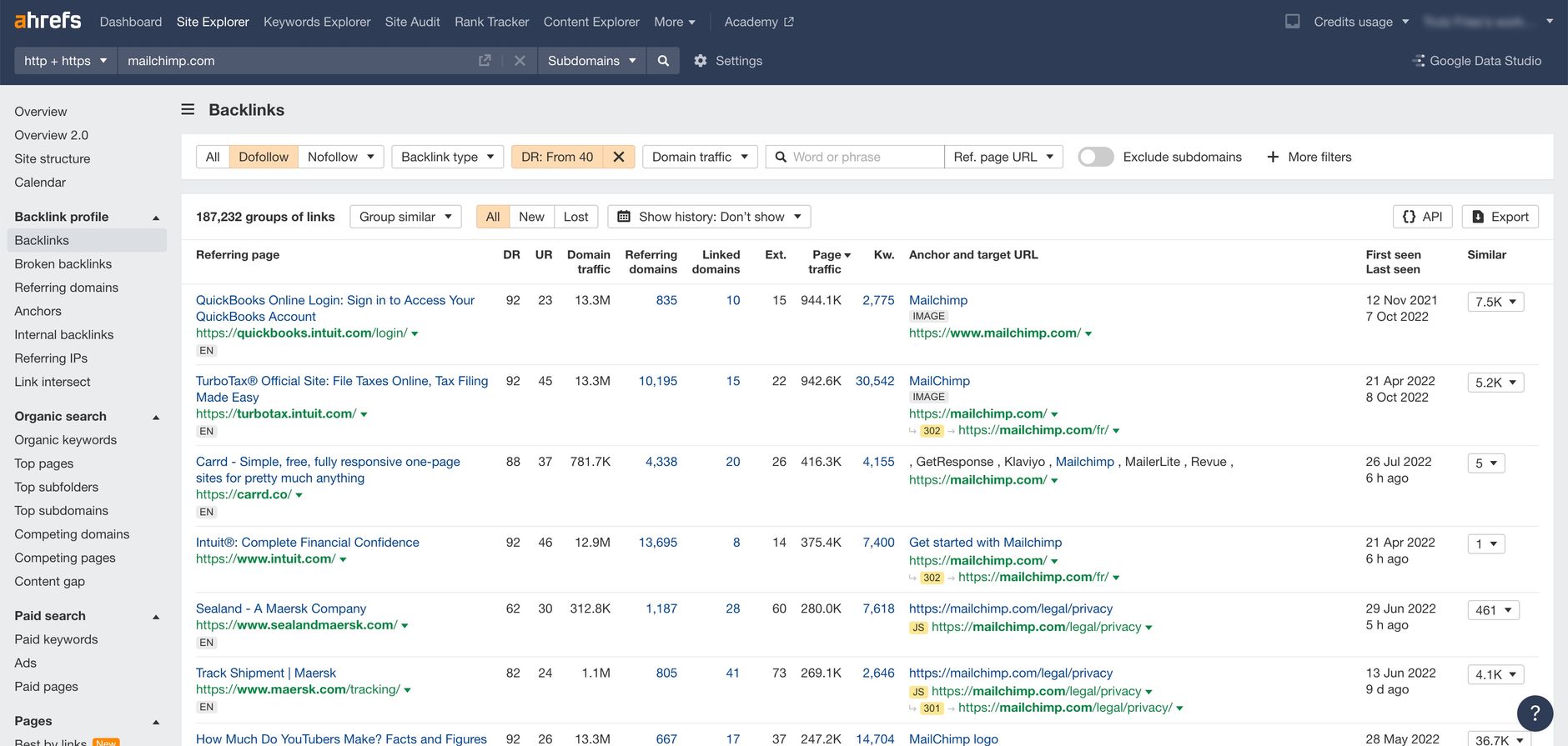
If you are on the "Lite" plan, exports are limited to 2,500 rows. If a domain has many more backlinks, it makes sense to restrict the results to e.g., "dofollow" links with a higher domain rating (DR). This way we exclude low quality links early on. But don't worry, if you download all links at this stage. Later we'll some filters to excluded links by domain rating again.

We then download the result set and save it all into a separate folder:
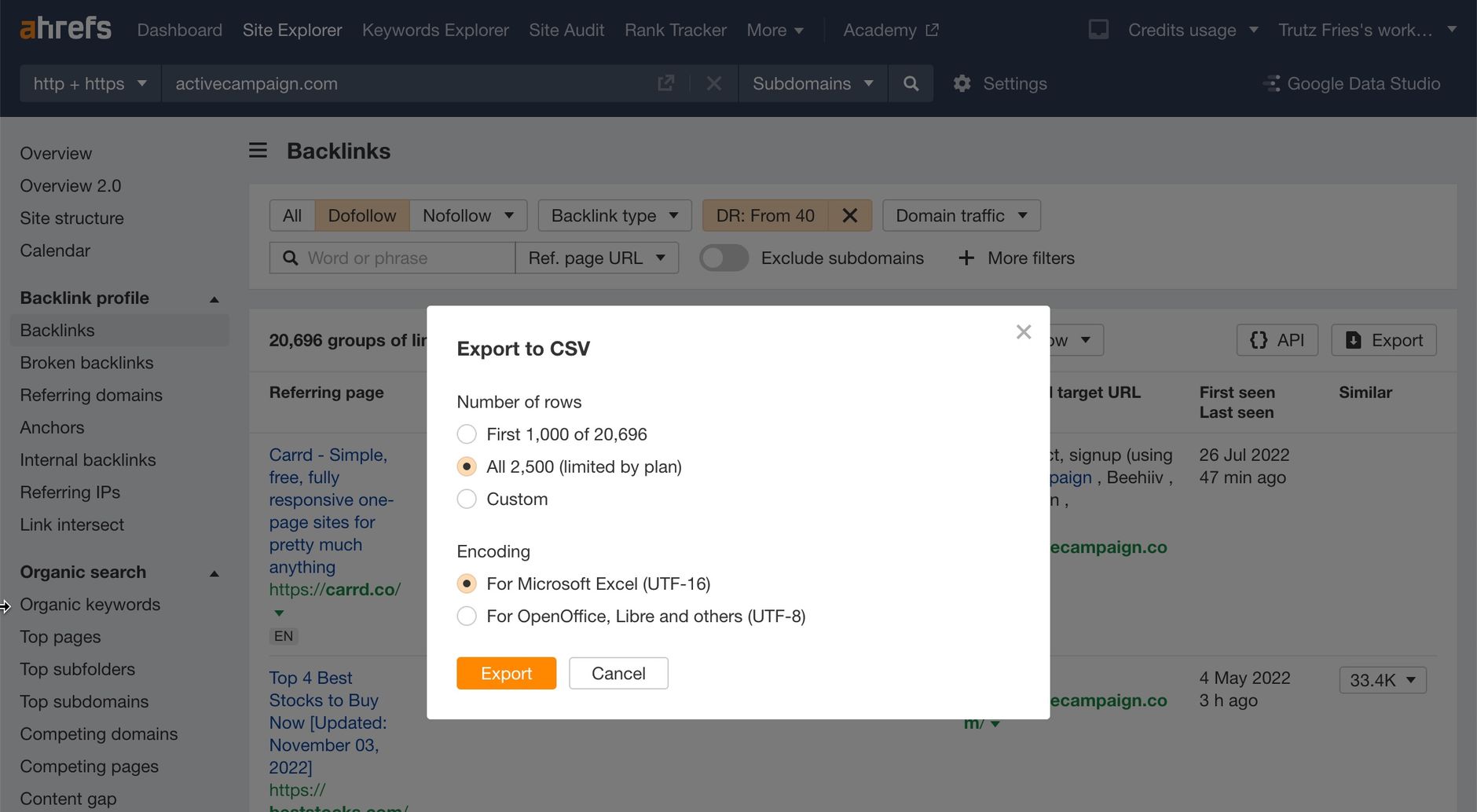
Please note that we use the UTF-16 encoding here. Feel free to choose UTF-8. However, you need to adjust the code below in this case.
Once completed, your local folder should look like this:
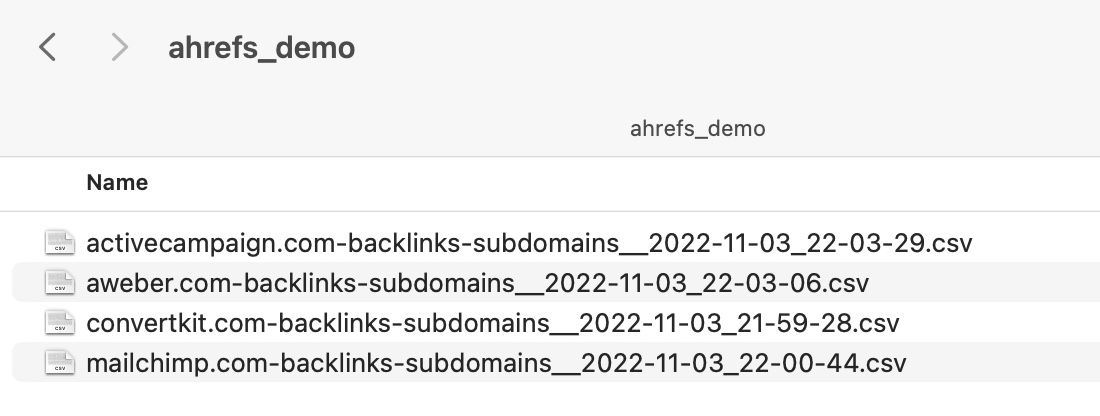
Now we have all the data we need. So it's time to code!
Loading ahrefs backlink data into Python
Let's load the necessary libraries first. We do not need many:
import re
import os
import pandas as pd
import numpy as np
from urllib.parse import urlparse
import openpyxl
pd.set_option('display.max_colwidth', None)
pd.set_option('display.max_columns', None)
We then set some variables:
my_root_domain = 'convertkit.com'
min_dr_rating = 50 # Include only links from domains with a DR > min_dr_rating
ahrefs_path = 'ahrefs_demo/' # Export CSV files as UTF-16 to this directory
Even if you set strict filters for the domain rating, you'll find domains you don't want to include in your reports, so let's define an array of those domains which we filter out later:
# Spammy domains you don't want to include in your results
discardDomains = ["000webhostapp.com", "kucasino.me", "aikido.itu.edu.tr", "angelsofmumbai.in", "iguassuflatshotel.siteoficial.ws", "789betting.com", "istanbulaarschot.c1.biz", "martech.zone", "developmentmi.com"]
Let's load the CSV we downloaded in the previous step:
ahrefs_filenames = os.listdir(ahrefs_path)
ahrefs_df_lst = list()
ahrefs_colnames = list()
# Read all CSV files (they were exported as UTF-16 which makes classic pd.read_csv fail)
for filename in ahrefs_filenames:
if filename.endswith(".csv"):
with open(ahrefs_path + filename, encoding='UTF-16') as f:
df = pd.read_csv(f, sep='\t', error_bad_lines=False, encoding='utf-8')
df['site'] = filename
df['site'] = df['site'].str.replace('www.', '', regex = False)
df['site'] = df['site'].str.replace('.csv', '', regex = False)
df['site'] = df['site'].str.replace('-.+', '', regex = True)
ahrefs_colnames.append(df.columns)
ahrefs_df_lst.append(df)
ahrefs_df_raw = pd.concat(ahrefs_df_lst)
ahrefs_df_raw
We also added one additional column called site which takes the filename and strips the domain name from it. This way we know where the links came from.
We then add all backlinks to a single dataframe called ahrefs_df_raw.
The result should look like this now:
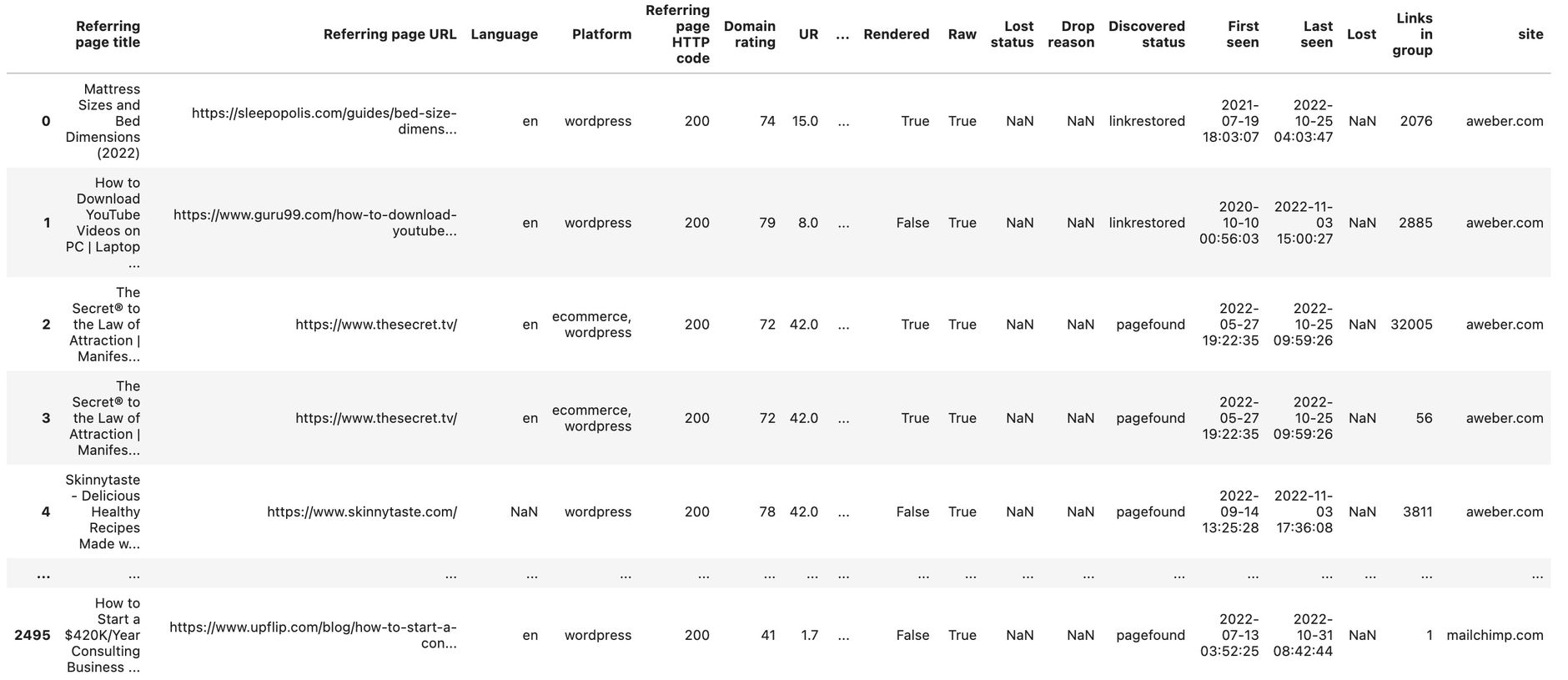
Now we need to clean things up a bit.
Cleaning the ahrefs backlink data
Let's change the column names so working with them becomes easier:
df_temp = ahrefs_df_raw
df_temp.columns = [col.lower() for col in df_temp.columns]
df_temp.columns = [col.replace(' ','_') for col in df_temp.columns]
df_temp.columns = [col.replace('.','_') for col in df_temp.columns]
df_temp.columns = [col.replace('__','_') for col in df_temp.columns]
df_temp.columns = [col.replace('(','') for col in df_temp.columns]
df_temp.columns = [col.replace(')','') for col in df_temp.columns]
df_temp.columns = [col.replace('%','') for col in df_temp.columns]
Hat tip to Andreas Voniatis. I used some parts of his script to load and prepare the data.
Now we add some additional columns, which will help us later.
We'll add a simple column called count, which allows us to quickly sum the number of links in our pivot table.
We also create a new column called referring_page_domain where we extract the top-level domain from the referring_page_url column for easier grouping. A simple lambda function leveraging the urlparse library does the trick.
# Add simple count column
df_temp['count'] = 1
# Add top-level domain to new column name "referring_page_domain"
def get_base_domain(url):
return urlparse(url).netloc.replace('www.','')
df_temp['referring_page_domain'] = df_temp.apply(lambda x: get_base_domain(x['referring_page_url']), axis=1)
We now remove some results we don't want to include. These are the domains we defined earlier in discardDomains, and we also remove links of the type redirect.
# Drop rows that contain domains from discdiscardDomains array
df_temp = df_temp[~df_temp['referring_page_url'].str.contains('|'.join(discardDomains))]
# Drop redirect links
df_temp = df_temp[df_temp["type"].str.contains("redirect") == False]
# Copy the result to the df dataframe
df = df_temp
Our dataframe now should look like this:
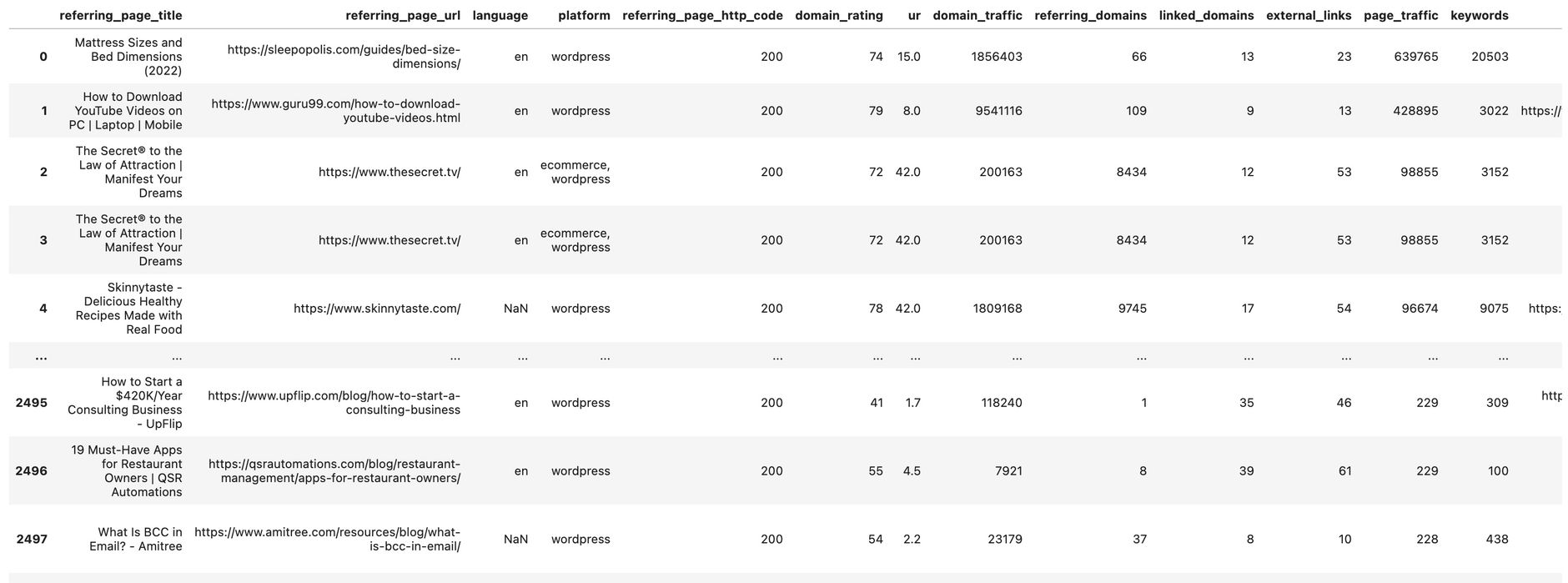
We now create some more helper dataframes we later use to join this data. Here we create a dataframe that contains the ahrefs domain rating for each domain:
dfDomainRating = df.groupby(['referring_page_domain'])['domain_rating'].mean()
dfDomainRating.reset_index()
This dataframe should look like this:
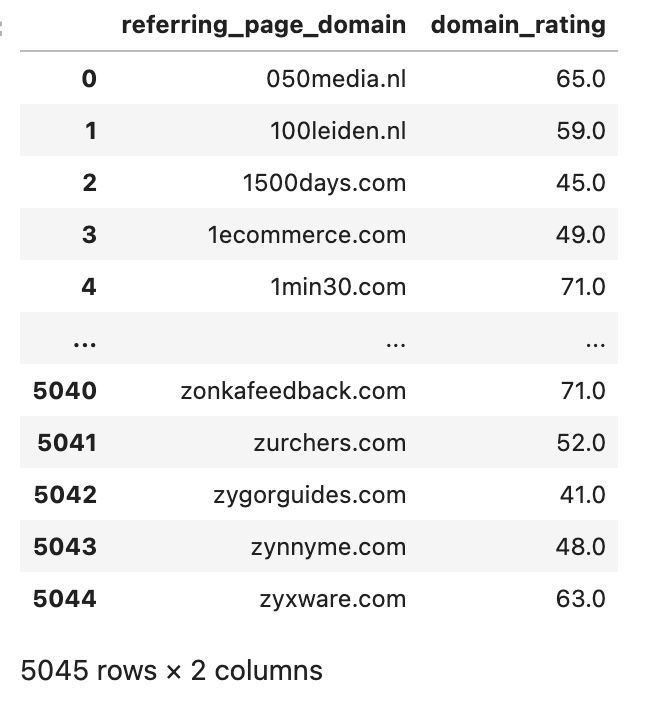
Later we group by the referring domain, but we would like to show some example URL, so we create a dataframe that contains only the first result for each domain. Later we'll also "left join" this data.
df2 = df.drop_duplicates('referring_page_domain')
df_domain_with_example_url = df2[['referring_page_domain', 'referring_page_url', 'anchor', 'type']].copy()
The result looks like this:
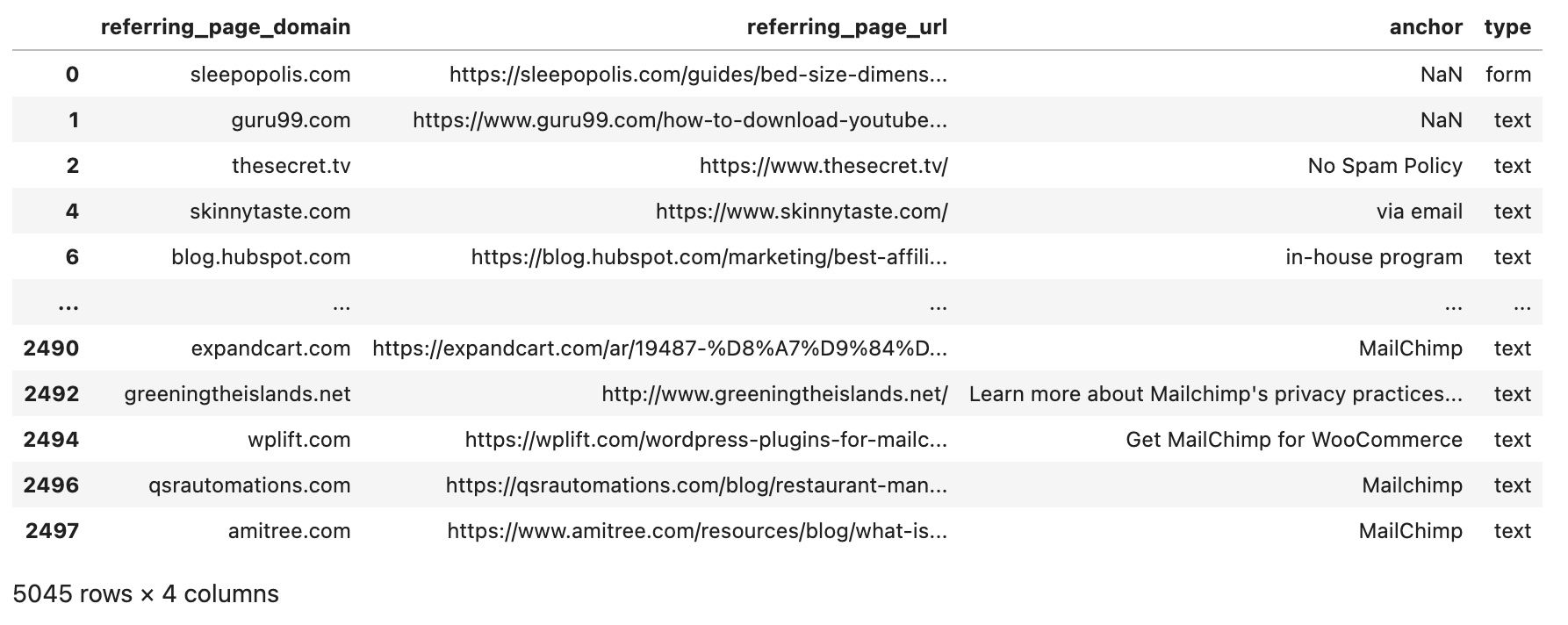
Creating ahrefs link intersect reports
Now we can create a pivot table that shows us which referring domain links how often to our four sites of interest incl. our own:
dfPivot = pd.pivot_table(df[df.domain_rating > min_dr_rating], values = 'count', index=['referring_page_domain'], columns = 'site', aggfunc=np.sum).reset_index()
dfPivot = dfPivot.fillna(0) # Transform NaN values to 0
Now we left join the domain rating data from our helper dataframe:
df_pivot_with_domain_rating = pd.merge(dfPivot, dfDomainRating, on='referring_page_domain', how='left').sort_values(by=['domain_rating'], ascending=False)
This dataframe will look like this:
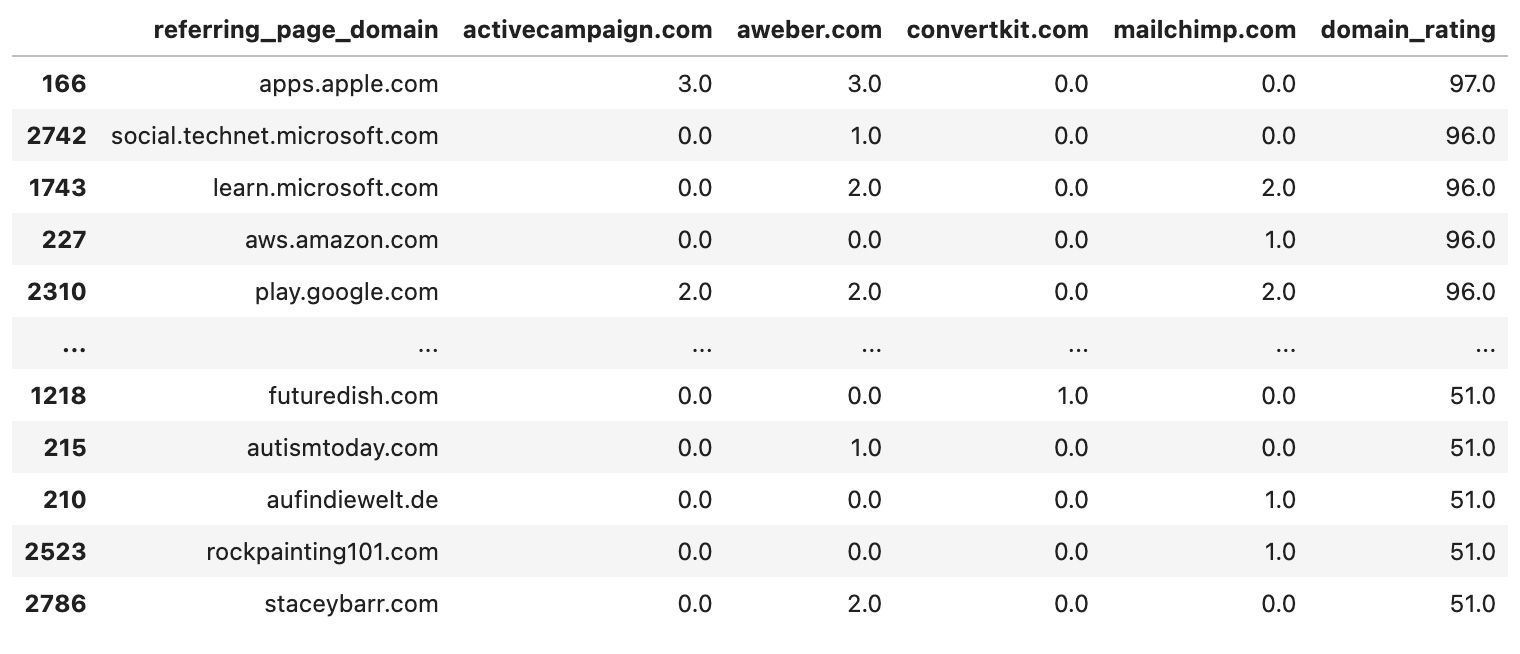
And we also add our sample data:
df_final = pd.merge(df_pivot_with_domain_rating, df_domain_with_example_url, on='referring_page_domain', how='left').sort_values(by=['domain_rating'], ascending=False)
# Rename one column
df_final.rename(columns={'referring_page_url':'example_url'}, inplace=True)
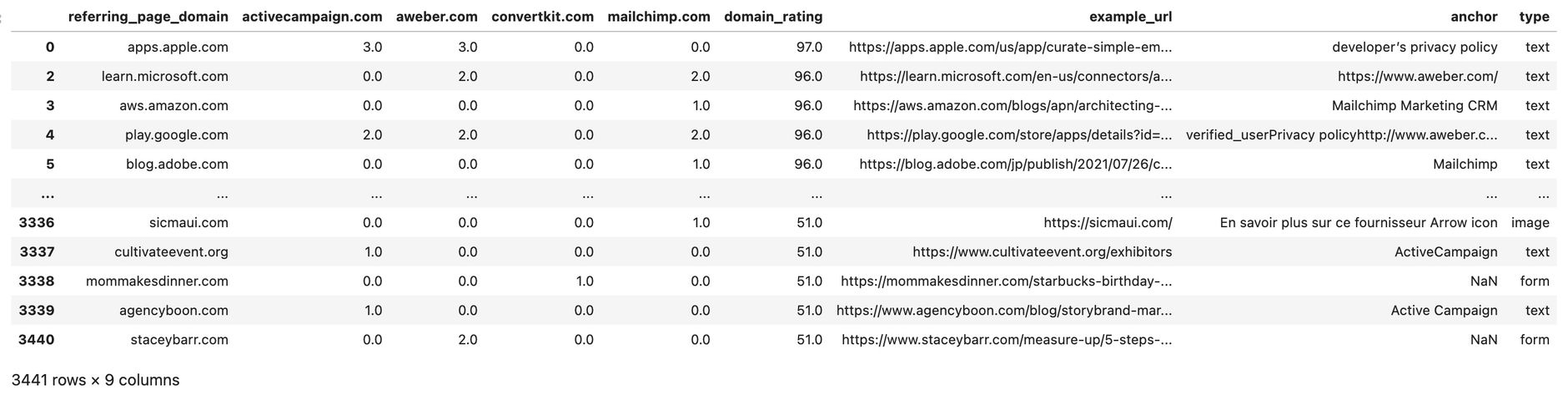
And there we have it. For further review, we save all our results to Excel in the next step.
Export data to Excel
Let's save both the pivot table and also the underlying data as a handy Excel file:
with pd.ExcelWriter(my_root_domain + '-ahrefs-output.xlsx', engine='openpyxl') as writer:
df_final.to_excel(writer, sheet_name='Pivot', index = False, header=True)
df.to_excel(writer, sheet_name='All', index = False, header=True)
Show link building opportunities
If you want to get a preview of links you don't have, but your competitors have, just use this simple filter:
df_final[df_final[my_root_domain] == 0]
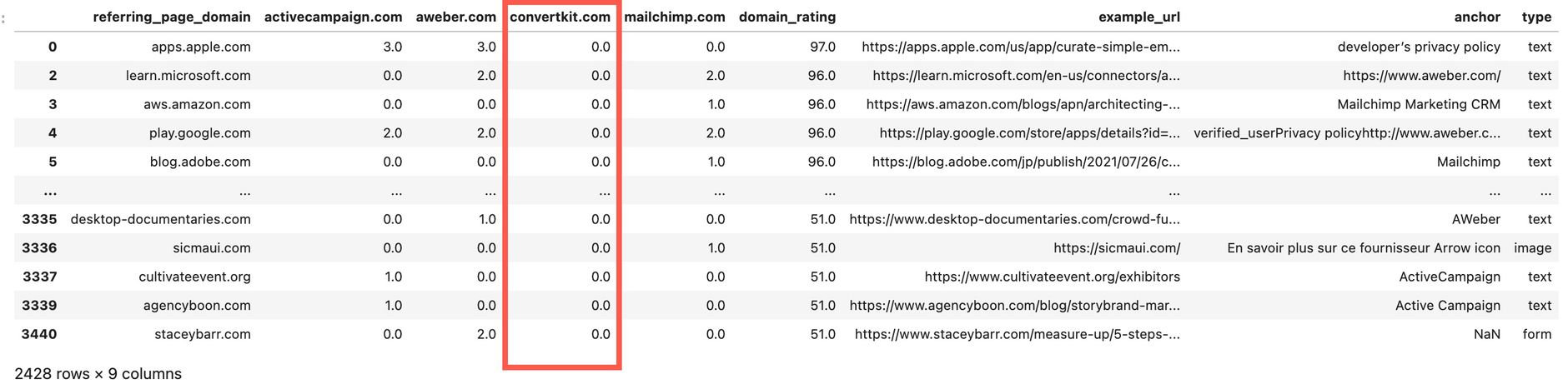
If you want to check the links you do already have, use this filter condition:
df_final[df_final[my_root_domain] > 0]
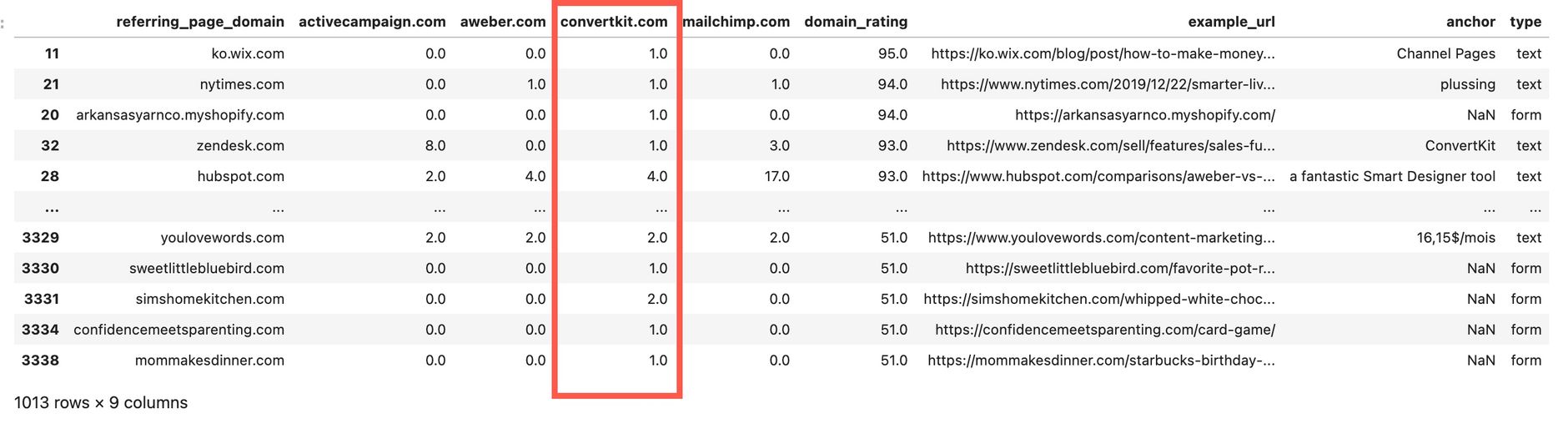
If you open the created Excel file this should look like this:
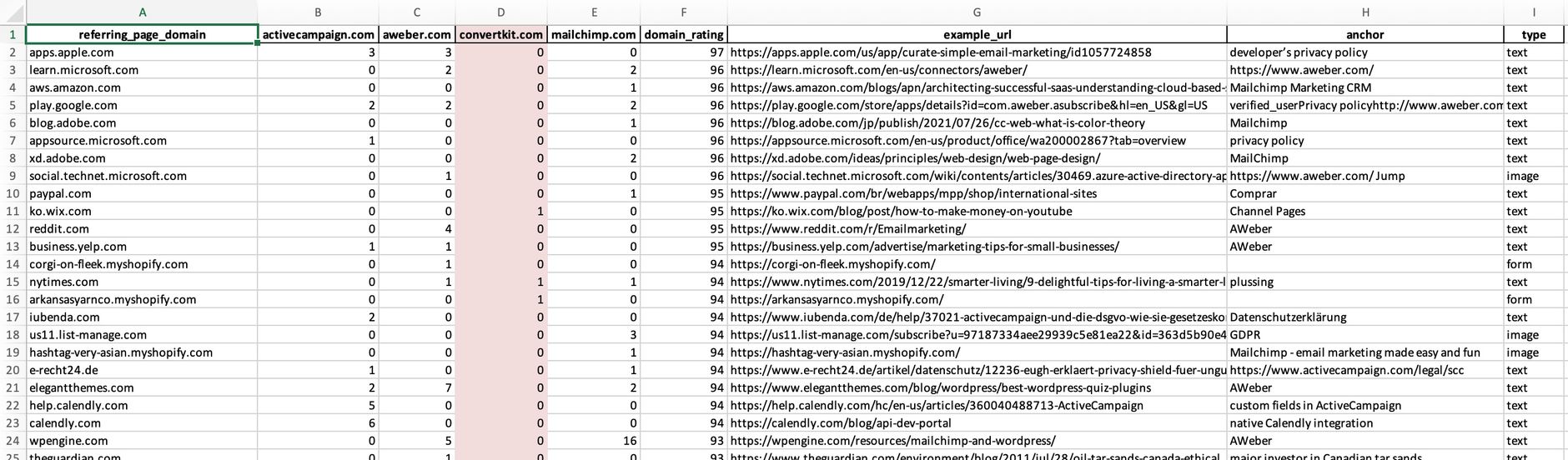
You can now use, e.g. the auto-filter to further narrow down results.
Most often you quickly find domains you would like to exclude. You should add them to our discardDomains array. Running the script again only takes seconds.
Of course there is much more you can do with this script. E.g., you can use other or more metrics to narrow down the long list of backlinks.
So feel free to experiment with it and let us know what you did. Good luck!



